Are you looking for more details to start or take you ahead on your certification journey? Check out the links below that may answer all your questions.
Read MoreChoose a CBCA Credential. It will advance your professional career. CBCA Credential helps you to stand out from the crowd.
Apply NowAre you looking for more details to start or take you ahead on your certification journey? Check out the links below that may answer all your questions.
Read MoreChoose a CBCA Credential. It will advance your professional career. CBCA Credential helps you to stand out from the crowd.
Apply NowAre you looking for more details to start or take you ahead on your certification journey? Check out the links below that may answer all your questions.
Read MoreChoose a CBCA Credential. It will advance your professional career. CBCA Credential helps you to stand out from the crowd.
Apply NowAre you looking for more details to start or take you ahead on your certification journey? Check out the links below that may answer all your questions.
Read MoreChoose a CBCA Credential. It will advance your professional career. CBCA Credential helps you to stand out from the crowd.
Apply Now

At first, there were rows and columns, well, there still are. Databases have come a long way since the earliest days of Integrated Data Store and the CODASYL. Relational Database Models followed, and then the era of Structured Queries began, Extensible Markups came soon thereafter, and Not Only SQL was the last big thing. Database models have evolved, it would seem, almost as fast and as much as computing itself has.
Finally, the game changer was born, as prophesied, and database models were never the same again. Between then and now, the story hasn’t been just about data models. It has been about computing, hardware, storage, networks and development evolution too.
The era of decentralized computing isn’t merely about decentralized storage, the same way blockchain is not merely a decentralized relational database. To those not in the know, however, blockchain may sound like a distributed, encrypted database and nothing more. That’s pretty much as far from the truth as it can get. Apples and oranges, really. To begin with:
Client-Server and Server Administration no more. Blockchain functions on the very premise of distributing the roles and responsibilities of the database administrator to users who are also known as the participants within the blockchain networks. The very nature of the technology democratizes the entire data model administration process. Decentralization, in other words. Decisions on almost all facets of the blockchain network between peers are taken by a majority consensus. This entire peer to peer data model, distributed among nodes, is the foundation of blockchain and its hitherto most popular implementation, the cryptocurrency.
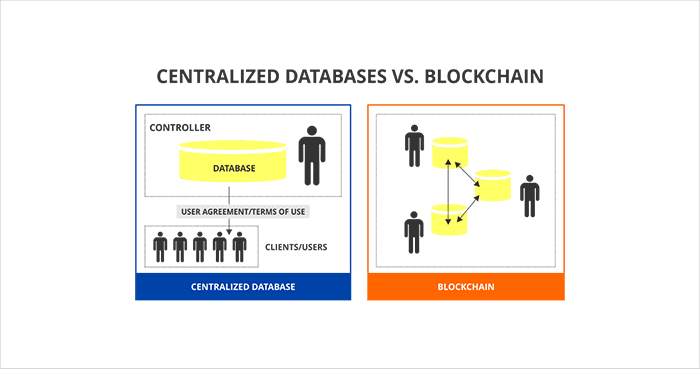
The blockchain management model is fairly indicative of the concept of decentralization that forms its foundation. Unlike traditional databases with its hierarchical models of administration and transaction processing that involves one or more third party to be processes successfully, transactions within the blockchain are conducted without any intermediaries. Based on the principle of consensus, transaction processing is safe, accurate and efficient. This also extends to the other end of the spectrum, where users within the blockchain are only allowed to add, not edit or delete any data. Immutable record keeping ensures that the data contained in the blockchain cannot be tampered with, regardless of the party in question. Compare this to the traditional relational database that allows all its users, depending on rights provided by the administrator, to create, read, update or delete records. In fact, immutability of transaction records is a key driver of blockchain acceptability in transation sensitive sectors like Banking, Finance and Insurance.
Like every technology-hacker movie you’ve probably seen, the database is, well, centralized and vulnerable in real life, too. Security in the blockchain, however, is completely transformed into something of a magic trick – Decentralized blocks residing in private peer-to-peer nodes that are completely encrypted and compressed at each node.
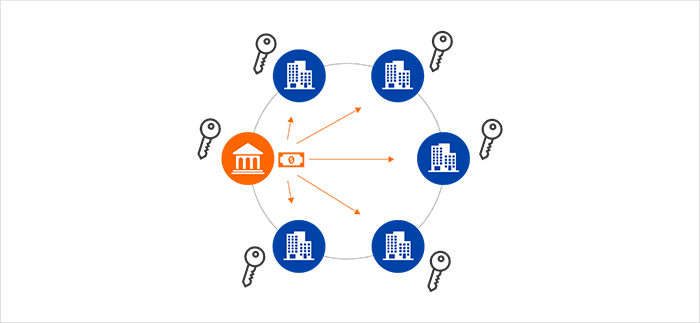
A simple way to comprehend the complexity of the blockchain security architecture is to think of the database as little bits, each locked individually. When there’s no single point of entry to hack, non- network participants are an eliminated threat.
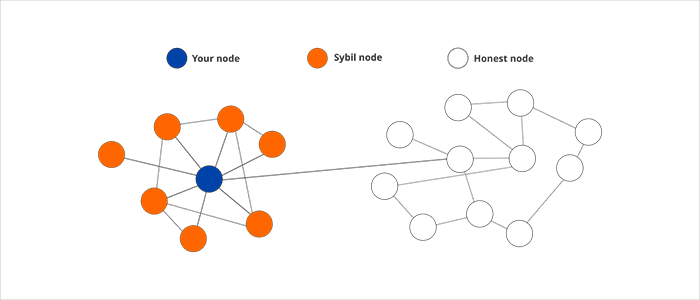
An interesting spin on the blockchain security concept is the “Sybil” hack, not unlike a Trojan horse, where a participant within the blockchain, attempts to control a peer network by creating multiple fake identities. The name originates from Flora Rheta Schrieber’s seminal book about her patient who suffers from multiple personality disorders. The dynamics and structure of a Sybil attack on its network can be accurately summed up in the diagram below:
We may have evangelized blockchain as the one answer against all odds of the database/blockchain face off, and for all the right reasons, blockchain has dark horse in the next era of data models and storage technologies, but performance, unfortunately, remains the last remaining bastion for traditional databases. Let’s face it, nothing beats the speed of a single data model regardless of structure, eliminating the complexities of consensus and encryption (most databases have their own safety checks and balances in place). The entire engineering of a database that is in the market is usually immaculate, and the latency is super low, powerhouse performance is a given.
The blockchain negates all that, with its dependency on computational capability of every node within the chain, followed by the dependency of how many nodes there actually are in the chain, the possible downtime in network connectivity, to name just a few. Seems like a lot of challenges for blockchains, whether private or public, to be overcome before they get to the mainstream adoption that NOSQL relational database models still enjoy.
Blockchain trumps traditional databases in almost every aspect except cold hard latency and performance metrics, besides user rights management within the blockchain network. While this may sound fairly simple for the blockchain entrepreneurs of the world to overcome, it’s striking that they still haven’t gotten down to it. Maybe the world is looking for the next bright mind to give the reborn blockchain a boon of high performance in Blockchain 4.0?




